
한글 검색기 만들어보기
주식에 대한 정보를 제공해주는 앱이 있다고 하자.
사용자는 원하는 종목을 검색하고 싶다.
검색창에 한글자, 한글자 입력할 때마다 javascript 는 해당 글자에 관한 검색 결과를 반환한다.
검색 결과는 중요도 우선순위로 정렬되어 보일 수 있는데, 사람들이 많이 클릭했던 순, 시가총액 순 등의 기준을 세울 수 있을 것이다.
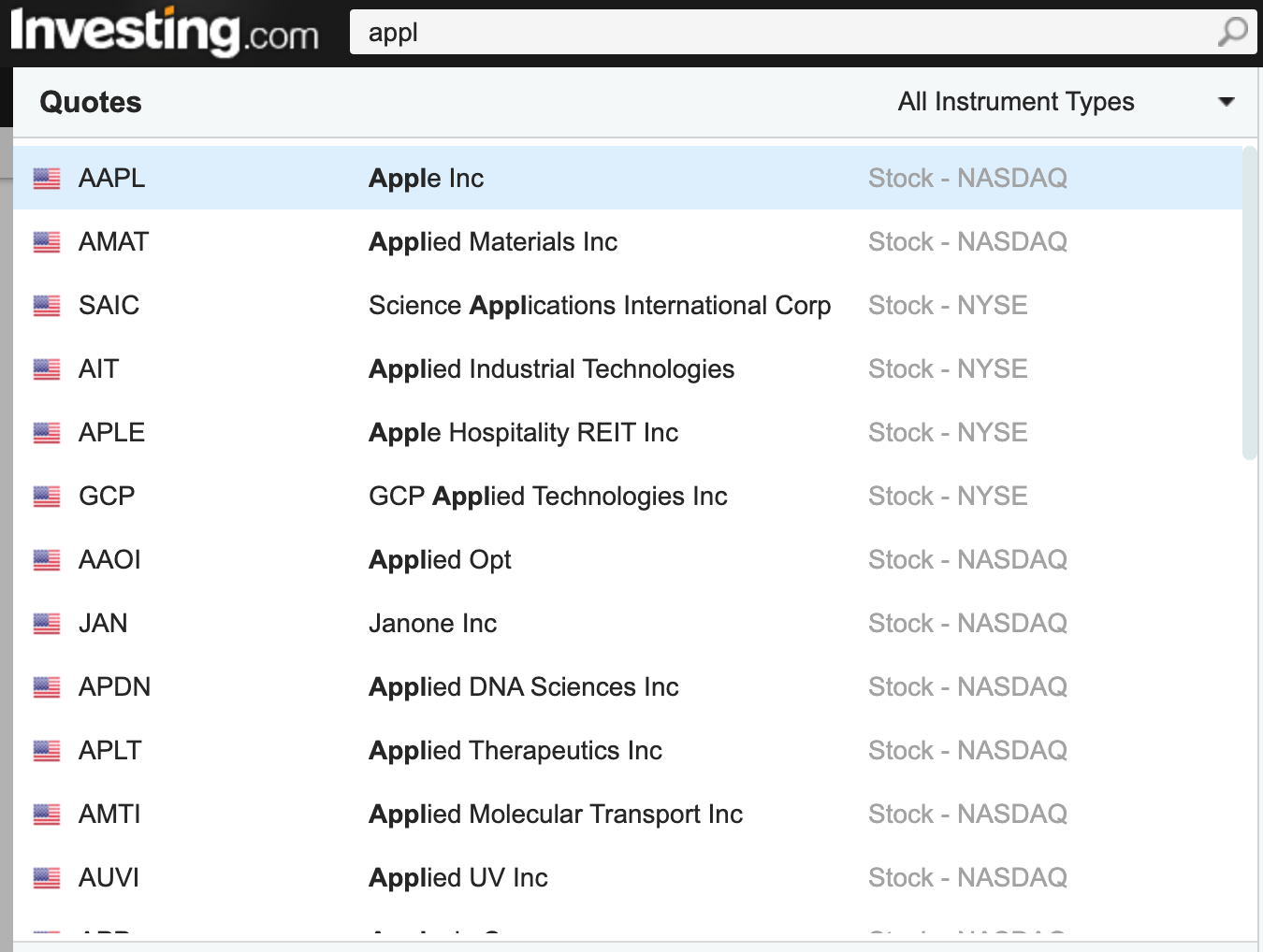
위 그림의 결과를 예시로 들 수 있다.
우리는 이를 로직으로 구현하기 위해 sql 에서 like 구문을 생각해볼 수 있다.
SELECT item_name
FROM item
WHERE item_name like '%'||:keyword||'%'- item 테이블에는 종목이름이 들어있다.
위 쿼리는 like 검색이기 때문에 인덱스 적용이 힘들고, 원하는 성능의 결과를 얻을 수 없을 수도 있다.
혹은 앞글자만 정확히 입력하면 뒷글자만 비슷하게 찾아주는 검색방식으로 타협을 볼 수도 있다. (아래와 같이하면 인덱스는 사용할 수 있다.)
SELECT item_name
FROM item
WHERE item_name like :keyword||'%'Like 검색은 비효율적일 수 있지만 간단하게 생각해볼 수 있는 가장 단순한 구현이면서도, 문자열의 길이가 짧고 데이터의 수가 적은 케이스의 경우 잘 사용될 수 있는 방법이기도 하다.
더 복잡한 데이터를 다루기 위해서는 Elasticsearch 와 같이 역색인을 사용하는 검색 엔진, 자연어 처리 분석 등의 도입을 고려해볼 수 있다.
이 글에서는 sql 을 통해 검색하는 것만 다룬다.
한글은 글자의 구성이 조금 다르다.
영어의 경우, apple 의 알파벳구성은 a, p, p, l, e 로 확실하게 나누어져있다.
글자가 확실히 나누어져 있고, 알파벳들은 모두 like 검색이 가능하다.
하지만 한글의 경우를 생각해보면, 검색어 애플은 애, 플로 나누어져 있다.
'앺' 을 검색했을 때도 애플이 나오도록 하고싶다면, 위에서 작성한 sql 와 지금의 테이블 구성으로써는 작동이 어렵다.
자판을 입력하는 과정을 생각해보자.
애플을 검색하는 경우 :
ㅇ → 애 → 앺 → 애프 → 애플검색창에 적히는 글자는 위의 5개 순서로 적용이 된다.
생각해보면 ㅇ, 앺, 애프 로 검색했을 경우는 원하는 검색결과가 안나온다는 것을 알 수 있다.
IDEA
애플이라는 단어의 '애', '플'과 같이 소리나는 단위 한 글자를 '음절' 이라고 한다.
하지만, 우리의 니즈는 음절 단위보다 하나 더 작은 단위를 원한다.
애플은 'ㅇ', 'ㅐ', 'ㅍ', 'ㅡ', 'ㄹ' 로 나눌 수 있고, 이를 '음소' 라고 한다.
즉, 테이블에 종목이름으로 '애플' 이 담겨있다면 이를 'ㅇㅐㅍㅡㄹ' 로 분리해주면 된다는 방법을 생각해볼 수 있다.
그러면 'ㅇ' 을 키워드로 검색해도 like 검색이 가능하고,
'앺' 키워드를 검색하는 경우 'ㅇㅐㅍ' 로 나누어 키워드를 입력한다면 like 검색이 가능하다.
초중성을 분리하는 방법
자바에서는 Normalize 가 글자를 분해/합성하는 기능을 지원한다.
private void printWord(String word) {
for (int i = 0; i< word.length(); i++) {
int codePoint = word.codePointAt(i);
System.out.println(word.charAt(i) + String.format(" U+%04X ", codePoint) + codePoint);
}
System.out.println();
}
String word = "애플";
printWord(word);
String nfd = Normalizer.normalize(word, Normalizer.Form.NFD);
printWord(nfd);애 U+C560 50528
플 U+D50C 54540
ᄋ U+110B 4363
ᅢ U+1162 4450
ᄑ U+1111 4369
ᅳ U+1173 4467
ᆯ U+11AF 4527
- Normalizer.Form.NFD 를 사용하여 한글을 정규화하면 한글을 각 음소별로 나누어준다.
- 각 음소의 유니코드값과 코드포인트 값을 출력하였다.
- 코드포인트(Code Point)
- 문자열에 할당된 코드값이다.
- 동일한 문자열에 할당된 코드값이더라도 인코딩 종류마다 다르게 표현된다.
다른 종목도 넣어보았다.
String word = "애버크롬비 & 피치";애 U+C560 50528
버 U+BC84 48260
크 U+D06C 53356
롬 U+B86C 47212
비 U+BE44 48708
U+0020 32
& U+0026 38
U+0020 32
피 U+D53C 54588
치 U+CE58 52824
ᄋ U+110B 4363
ᅢ U+1162 4450
ᄇ U+1107 4359
ᅥ U+1165 4453
ᄏ U+110F 4367
ᅳ U+1173 4467
ᄅ U+1105 4357
ᅩ U+1169 4457
ᆷ U+11B7 4535
ᄇ U+1107 4359
ᅵ U+1175 4469
U+0020 32
& U+0026 38
U+0020 32
ᄑ U+1111 4369
ᅵ U+1175 4469
ᄎ U+110E 4366
ᅵ U+1175 4469
이제 종목테이블에서 아래와 같이 한글을 분해시키고,
item
name decomposed_name
애플 ㅇㅐㅍㅡㄹ
애브비 ㅇㅐㅂㅡㅂㅣ
애버크롬비 ㅇㅐㅂㅓㅋㅡㄹㅗㅁㅂㅣ
페이스북 ㅍㅔㅇㅣㅅㅡㅂㅜㄱ
넷플릭스 ㄴㅔㅅㅍㅡㄹㄹㅣㄱㅅㅡ
keyword 에 분해된 한글을 넣어서 검색하면 된다.
즉, 키워드가 '애' 라면 'ㅇㅐ'로 분해하여 검색하는 것이다.
SELECT item_name
FROM item
WHERE item_name like '%'||:keyword||'%'애플
애브비
애버크롬비
앗 그런데, 초성과 종성이 다르다?
Normalizer.Form.NFD 를 사용하면 완성형 한글을 간단하게 초, 중, 종성으로 나누어 주지만, 초성과 종성의 모든 글자가 완전히 다르게 매핑된다.
즉, '넷플릭스'에서 '플'의 ㄹ 받침과 '릭'의 ㄹ은 다른 유니코드로 분리된다는 것이다. 하지만 우리가 원하는 검색을 위해서는 둘은 같음 음소로 분리해야 한다. 따라서 초중성을 분리하는 함수를 직접만들어보자.
public String seperate(String string) {
// 초성 19개
String[] arr_cho =
{"ㄱ", "ㄲ", "ㄴ", "ㄷ", "ㄸ", "ㄹ", "ㅁ", "ㅂ", "ㅃ", "ㅅ", "ㅆ", "ㅇ", "ㅈ", "ㅉ", "ㅊ", "ㅋ", "ㅌ", "ㅍ", "ㅎ"};
// 중성 21개
String[] arr_jung =
{"ㅏ", "ㅐ", "ㅑ", "ㅒ", "ㅓ", "ㅔ", "ㅕ", "ㅖ", "ㅗ", "ㅘ", "ㅙ", "ㅚ", "ㅛ", "ㅜ", "ㅝ", "ㅞ", "ㅟ", "ㅠ", "ㅡ", "ㅢ", "ㅣ"};
// 종성 28개
String[] arr_jong =
{"", "ㄱ", "ㄲ", "ㄳ", "ㄴ", "ㄵ", "ㄶ", "ㄷ", "ㄹ", "ㄺ", "ㄻ", "ㄼ", "ㄽ", "ㄾ", "ㄿ", "ㅀ", "ㅁ", "ㅂ", "ㅄ", "ㅅ", "ㅆ", "ㅇ", "ㅈ", "ㅊ", "ㅋ", "ㅌ", "ㅍ", "ㅎ"};
StringBuffer sb = new StringBuffer();
for (int i=0; i<string.length(); i++) {
char uniVal = string.charAt(i);
try {
if (uniVal >= 0xAC00 && uniVal <= 0xD7A3) {
uniVal = (char)(uniVal - 0xAC00);
char cho = (char)(uniVal / 28 / 21);
char jung = (char)(uniVal / 28 % 21);
char jong = (char)(uniVal % 28);
sb.append(arr_cho[cho]);
sb.append(arr_jung[jung]);
sb.append(arr_jong[jong]);
} else {
sb.append(uniVal);
}
} catch (RuntimeException e) {
sb.append(uniVal);
}
}
return sb.toString();
}한글 완성형의 유니코드 범위는 0xAC00 ~ 0xD7A3 이므로 해당 범위에서는 초중성을 분리하는 함수이다.
그 외의 문자는 변환되지 않고 그냥 나온다. try ~ catch 로 감싸준 이유는 혹시나 저 유니코드 사이에 속한 문자가 한글이 아닌 경우 들어갔다가는 out of index 에러를 반환시키기 때문에 추가해보았다. 한글만 들어온다는 확신히 든다면 제거해도 좋다.
Normalizer 이용
ᄂ U+1102 4354
ᅦ U+1166 4454
ᆺ U+11BA 4538
ᄑ U+1111 4369
ᅳ U+1173 4467
ᆯ U+11AF 4527
ᄅ U+1105 4357
ᅵ U+1175 4469
ᆨ U+11A8 4520
ᄉ U+1109 4361
ᅳ U+1173 4467
---------------------------------
seperate 함수이용
ㄴ U+3134 12596
ㅔ U+3154 12628
ㅅ U+3145 12613
ㅍ U+314D 12621
ㅡ U+3161 12641
ㄹ U+3139 12601
ㄹ U+3139 12601
ㅣ U+3163 12643
ㄱ U+3131 12593
ㅅ U+3145 12613
ㅡ U+3161 12641
이렇게 초중성을 분리한 후, 테이블에 데이터를 저장해서, like 검색으로 키워드검색을 하면 되겠다. 인덱스 검색이 어렵기 때문에 성능은 보장하지 못하지만 종목검색 등과 같이 그 개수가 약간은 한정된 데이터에서는 어느정도 힘을 발휘할 수 있을 것이다. 성능을 보장하려면 검색엔진을 사용하자.
유니코드와 인코딩
자세한 원리를 알고싶다면 컴퓨터에서 문자를 표현하는 방법을 알 필요가 있다.
한글과 같은 다국어는 기본 아스키코드에 포함되어 있지않고, 유니코드에 표현되어 있다.
유니코드(Unicode)
- 세계에서 사용되는 모든 문자를 숫자코드와 1:1 대응시켜 컴퓨터에서 사용할 수 있도록 만든 코드표이다.
- U+ 접두어를 가진다.
- 예를 들어, A는 아스키코드 0x41를 가지고, 유니코드는 U+0041 이다.
- 아스키코드(ASCII) 는 128개의 문자가 코드에 매칭되어 있다.
- 다국어 기본 평면(BMP, Basic Multilingual Plane)은 유니코드가 표현하는 언어들에 대한 구성도이다. 0x0000부터 0xFFFF 까지 표기된다. 거의 모든 근대 문자, 특수문자, 한글, 통합한자 등이 담겨있다.
- 유니코드에서 한글 글자마디(가,나,...힇)는 U+AC00..U+D7AF 사이 범위이다. 그 외에도 다른 유니코드에 자모단위도 모두 들어있다.
- 유니코드 정규화 :
- 한글과 같은 결합문자에 대해 분리되고, 결합된 문자가 필요하다.
- 문자열 분해 (decomposition)
- 정준 등가(canonical equivalance) - 의미, 모양이 정확히 일치하는 문자를 분리하여 독립적인 코드포인트로 인식한다.
- 호환 등가(compatibility equivalance) - 의미는 같지만, 모양이 다를 수 있는 경우 서로 다른 문자열을 호환가능한 유사 문자열로 인식한다.
- NFD (Normalization Form Canonical Decomposition) : Mac OSX, UNIX 등에서 주로 사용되고, 모든 음절을 분해하여 저장한다. (ㅇ+ㅐ+ㅍ+ㅡ+ㄹ.txt)
- NFC (Normalization Form Canonical Composition) : Linux, Windows 등에서 주로 사용되고, 문자를 있는 그대로 저장한다. (애플.txt)
유니코드표에는 한글과 유니코드가 매칭되어 있으며, 컴퓨터에서 인식하기 위해서는 이 유니코드를 다시 2진법으로 바꾸어주는 인코딩의 과정이 필요하다.
인코딩(Encoding)
- 위 코드를 2진법으로 표현하는 방법이다.
- 종류로 UTF-8, UTF-16, EUC-KR, CP949 등이 있다.
- EUC-KR, CP949 경우 한글을 2바이트로 인코딩할 수 있으며, CP949은 EUC-KR의 확장이므로 더 많은 한글을 지원한다.
- UTF-8(Unicode Transformation Format-8), UTF-16 인코딩은 한글자가 1~4바이트 중 하나로 인코딩 될 수 있다. 1바이트 영역은 아스키코드를 표현할 수 있다. 한글은 3바이트 구간에 존재한다.
우리는 주로 UTF-8 을 많이 사용한다. (아스키코드를 호환할수 있고, 1~4바이트로 효율적이게 변환할 수 있다. 한글은 3바이트로 변환된다.)
'Infra > Database' 카테고리의 다른 글
| [springboot] mysql database - java (JPA) 연동 (4) | 2020.10.03 |
|---|---|
| MariaDB 다운로드, 계정 설정 (261) | 2020.07.31 |
| [Boostcourse] JDBC 설명 (659) | 2019.11.23 |
| [Boostcourse] SQL, MySQL (622) | 2019.11.21 |




댓글