
데이터 부족
데이터 수가 부족한 상황에서는 검증집합(validation, test)을 따로 마련하기 힘든데,
이 때 교차검증(cross-validation)을 이용하면 효과적입니다.
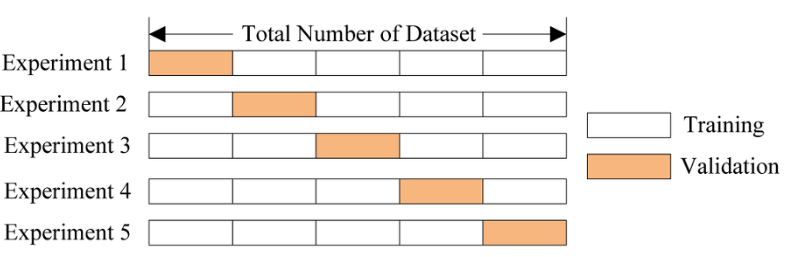
훈련집합을 같은 크기로 나누어 k개의 그룹을 만든 후,
1개는 검증그룹, 나머지 k-1개는 훈련그룹으로 나누어서 그룹을 달리하며 k번 반복합니다.

여기서 k개의 성능을 얻게 되는데, 이들을 평균하여 검증 성능으로 취합니다.
오버피팅
하지만 이렇게 할 경우 훈련과정에서 검증데이터가 개입을 하므로,
과대적합(overfitting)이 일어났는지에 대한 예측을 하기가 어렵습니다.
그래서 사용하는 방법은, 앙상블(ensemble)입니다.
예측방법은 보통 두가지로 나뉘지만 (회귀, 분류),
여기서는 분류(classification)를 예로들어 보겠습니다.
분류 문제가 있을 때,
전체 훈련 집합을 각각 훈련과 검증 집합으로 나눈 (train, validation) 세트 K개에 대하여
각각 학습을 시켜서, K개의 모델을 만들고,
각 모델을 이용하여
test세트의 각 데이터를 얼마나 잘 분류하였는지, 투표(vote)하는 것입니다.
예를 들어 모델이 5개가 있다면, 그 중 과반수인 3 모델 이상이 정답으로 분류했다면, 그 데이터는 올바르게 분류했다고 기준을 잡는 것입니다.
슈도 알고리즘은 다음과 같습니다.
훈련 집합을 k개의 그룹으로 분류한다.
for each i=1 to k
i번째 그룹을 제외한 k-1개의 그룹으로 모델을 학습시킨다.
(while (loss가 수렴할 때까지)
for each epoch
for each step
loss 계산
i번째 그룹으로 학습된 모델의 성능 측정
성능이 개선되었다면, 모델 업데이트)
학습시킨 k개의 모델을 앙상블하여 테스트 집합으로 모델의 성능을 측정한다.장단점
장점은 한번에 더많은 데이터 셋을 학습하여, 최적의 모델을 구하는데 도움을 줄 수 있는 반면,
그 만큼 한 에폭당 시간이 더 오래 걸린다는 단점이 있겠습니다.
하지만 K-fold cross validation은 데이터 수를 늘려 학습하는 효과와 더불어, 앙상블기법과 함께 사용하면, 테스트 셋에 대해 성능을 개선할 수 있는 방법입니다.
'ML, DL > Concept' 카테고리의 다른 글
| [ML] Semi-supervised Learning, Transfer Learning 설명 (599) | 2019.11.23 |
|---|---|
| [Regularization] 규제, 모델 일반화능력 향상, Model generalization (970) | 2019.10.07 |
| [DL] 딥러닝 성능 향상(전처리, 가중치초기화, 모멘텀, 활성함수) (0) | 2019.09.24 |
| 교차 엔트로피(Cross Entropy)와 로그우도(Log Likelihood) (2) | 2019.08.29 |
| [Classification] Cross entropy의 이해, 사용 방법(Categorical, Binary, Focal loss) (8) | 2019.08.01 |




댓글