
목적함수: 교차 엔트로피(Cross Entropy)와 로그우도(Log Likelihood)
MSE(Mean Square Error, 또는 L2 loss)로 살펴보기
정답레이블이 0인 상황에서 예측값(o)이 각각 0.7503, 0.9971 나온 두 경우를 생각해보자.
후자(0.9971)가 조금 더 큰 에러가 발생했으므로, 더 큰 그레디언트로 가중치(weight)를 갱신시켜 주어야 할 것이다.
하지만,
$$
e = \frac{1}{2}(y - o)^2 = \frac{1}{2}(y-\sigma(wx+b))^2 \ where, \sigma(x) = \frac{1}{1 + e^{-x}} (sigmoid)
$$
MSE 식에서 각각 파라미터 w와 b로 미분을 해보면,
$$
\frac{\partial e}{\partial w} = -(y - o)x\sigma'(xw + b) \
\frac{\partial e}{\partial b} = -(y - o)\sigma'(xw + b)
$$
다음과 같은 결과가 나오고,
계산을 해보면 전자는 0.0043, 후자는 0.0029만큼, 즉 전자가 더 크게 벌점을 받게 되었다.
에러가 더 큰 상황에 낮은 벌점을 주더라도, 그레디언트는 오류를 줄이는 방향을 제대로 제공해주므로 최저점을 찾아가는 데는 문제가 없다. 하지만 학습이 느리게 이루어지고, 이는 심각한 문젯거리이다.
원인은, 활성화함수 o가 sigmoid 였던 점이다.
위 그레디언트 식에서는 시그모이드 함수와 그 도함수가 같은 식에 들어있다.
시그모이드를 직접미분해보자
$$
y = \frac{1}{1 + e^{-x}} \
y' = \frac{e^{-x}}{(1+e^{-x})^2} = \frac{1}{1 + e^{-x}} \frac{e^{-x}}{1 + e^{-x}} = y(1-y)
$$
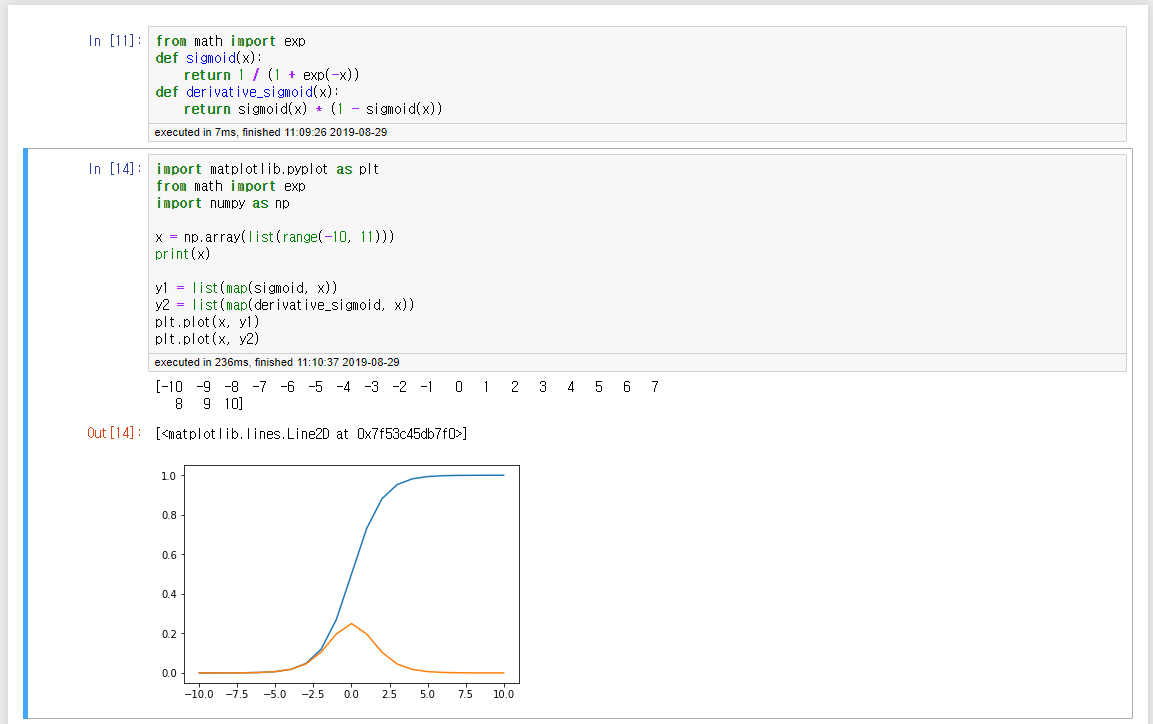
시그모이드를 미분하면 0에서 최댓값 1/4을 가지고, 절댓값 4이상으로 멀어지면 함숫값은 급격히 0으로 수렴한다.
다시말해 시그모이드의 도함수의 특징은, 0에서 최대값을 가지고 0에서 멀어지면 함숫값이 빠르게 0으로 수렴하는 것이다.
즉, wx+b가 커지면 그레디언트가 매우 작아질 수 밖에 없고,
그레디언트가 작아지면, 파라미터의 업데이트가 늦게 될 것이다.
따라서, 마지막 출력 층은 Sigmoid를 사용하되, 중간 층들에 대한 활성화함수로는 vansihing gradient가 일어나지 않는 ReLU를 자주 쓴다.
교차 엔트로피(CrosspEntropy) 목적함수
따라서, 딥러닝은 적어도 분류 문제에서는 로스함수로 MSE대신 CE(Cross Entropy)를 주로 사용한다.
(물론, 이를 확률분포로 생각한다면, 연속적인 값에 대한 손실함수는 가우시안 분포를 얻는다고 가정하는 MSE,
이산적인 값에 대해서는 멀티놀리 확률분포를 따를 것이라 가정하는 Cross entropy를 쓰는 것이 맞다.)
$$
H(P, Q) = - \sum_xP(x)log_2Q(x)
$$
여기서 상황을 간단히 하여, y 는 {0, 1}의 값을 가지는 확률변수이고, o가 신경망의 출력 확률변수라고 해보자.
즉, P가 정답 레이블, Q를 신경망 출력에 해당한다고 하면,
교차 엔트로피 목적함수를 쓸 수 있다.
$$
e = -(ylog_2o + (1-y)log_2(1-o)) \
where, o = \sigma(wx + b)
$$
이 목적함수 (loss 함수)가 제구실을 다하는 지 확인해보자.
y = 1, o = 0.98일 때 예측을 꽤나 잘한 것인데, 에러가 0.0291이 되어 매우 낮고,
y = 1, o = 0.0001이라면 예측이 엉터리 인데, 에러가 13.2877나 되어 매우 크다.
따라서 목적함수로 매우 적합한 함수라 할 수 있다.
위 loss e를 w와 b에 대해 미분해보자.
$$
\frac{\partial e}{\partial w} = - (\frac{y}{o} - \frac{1-y}{1-o})xo(1-o) v\
= x(o-y) \
\frac{\partial e}{\partial b} = (o - y)
$$
미분을 해보면, MSE와는 다르게 에러만으로 그레디언트값이 정해지고 있는 것을 알 수 있다.
즉 에러에 비례하여 가중치를 더 많이 수정하여 더 빠른 속도로 학습이 이루어질 것이다.
위는 클래스가 2개인 경우 {0, 1}인 binary cross entropy 를 보여주었다.
여러 클래스에 해당하는 cartegorical cross entropy의 식은 다음과 같다.
$$
e = - \sum_{i=1}^c(y_ilogo_i + (1-y_i)log(1-o_i))
$$
Softmax 활성함수(Activation Function)와 로그우도 목적함수
지금까지는 마지막 층 활성화함수로 Sigmoid 함수를 사용하였지만, 마지막 출력 노드의 경우 softmax를 사용하기도 한다.
$$
o_j = \frac{e^{s_j}}{\sum_{i=1}^ce^{s_i}}
$$
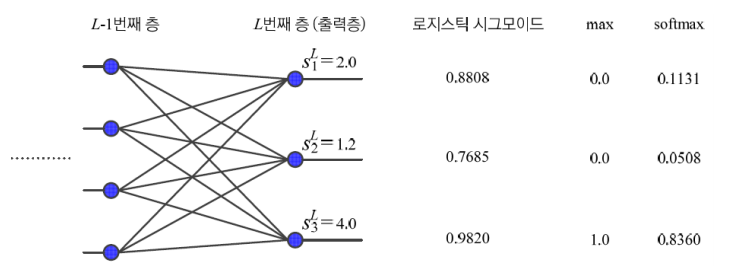
소프트맥스의 장점은 그림에서 보다시피, 최댓값과 최소값의 차이를 극명하게 드러내주어서,
그에 비례하는 가중치로 학습을 시키는 것이다.
softmax 활성화 함수의 짝으로 로그우도를 많이 쓰는데, 식은 다음과 같다
$$
e = -logo_y
$$
이 목적함수는 모든 노드값을 고려하는 평균제곱 오차나 교차 엔트로피와는 달리, Oy라는 하나의 노드값만 본다.
출력값이 1에 근접할 수록 e값은 0에 가까워진다. 즉, 목적함수로써 유용하다.
softmax는 최댓값이 아닌 값을 억제하여 0에 가깝게 만든다는 의도를 가진다.
따라서 학습샘플이 알려주는 부류에 해당하는 출력 노드값만 보겠다는 로그우도 목적함수와 잘 어울린다.
물론 softmax뒤 MSE나 CrossEntropy도 결합해 많이 쓰인다. 어떤 목적함수가 성능이 좋은지 보기위해서는 데이터별 실험하는 것이 최선이다.
출처: 기계학습, 오일석
'ML, DL > Concept' 카테고리의 다른 글
| [ML] Semi-supervised Learning, Transfer Learning 설명 (599) | 2019.11.23 |
|---|---|
| [Regularization] 규제, 모델 일반화능력 향상, Model generalization (970) | 2019.10.07 |
| [DL] 딥러닝 성능 향상(전처리, 가중치초기화, 모멘텀, 활성함수) (0) | 2019.09.24 |
| [ML] K-Fold Cross Validation (K겹 교차검증) (0) | 2019.08.02 |
| [Classification] Cross entropy의 이해, 사용 방법(Categorical, Binary, Focal loss) (8) | 2019.08.01 |




댓글