
Visual Explanations from Deep Networks via Gradient-based Localization
Ramprasaath et al, Virginia Tech, Georgia Institute of Technology, 2017
Abstract
CAM(Class Activation Mapping)은 CNN 기반 네트워크에서 많은 클래스를 결정할 때, 시각적인 설명을 제공합니다.
여기서 말하는 Grad-CAM(Gradient-weighted CAM)은 CAM을 구할 때,
"예측 이미지안의 중요한 부분을 강조하는 대략적인 지역 맵을 생산하기위한 마지막 컨볼루션 층으로 흘러가는",
"타겟 클래스(캡션, 마스크도 가능)에 대한" gradient를 이용합니다.
따라서 적용할 수 있는 범위가 넓어졌습니다.
1) fully-connected 층이 있는 CNN (VGG)
2) 구성된 output을 사용하는 CNN (captioning)
3) multimodal inputs 이 있는 CNN (VQA) 또는 강화학습
저자는 Grad-CAM을 사용함으로써 얻는 이점 5가지를 말했습니다.
1) 실패해보이는 예측에 대해 이것이 왜 실패했는지 설명을 해줄 수 있습니다.
2) 적대적(adversarial) 이미지에 대해도 적용이 잘됩니다.(robust)
3) 이전 방법인, ILSVRC-15 weakly-supervised localization task 의 성능을 뛰어넘었습니다.
4) 근본적인 모델에 대해 더 신뢰할만 합니다.
5) 데이터셋의 bias를 동일시하여(identifying) 모델 일반화를 달성합니다.
1. Introduction

2. Related Work
3. Approach

위 그림을 보면, 대략적인 이해에 도움이 됩니다.
Classification 문제에서 예를 들어보면, Grad-CAM( width=u, height=v 인 특정 클래스 c에 대한 이미지 )을 얻기위해
backprop을 통한 gradient 값들을 얻습니다.
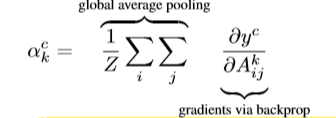
이를 위해 softmax 전 단계의 각 클래스에 대한 y score를, k번째 특징 맵 A에 대한 gradient를 얻습니다.
여기에 GAP(Global Average Pooling) 값과 곱하여 뉴런 중요도 가중치(neuron importance weight)인

를 얻습니다.

이렇게 얻은 가중치는 타켓 클래스 c에 대한 특징 맵 k의 중요도를 잡을 수 있는데요,
k개의 각 뉴런 중요도 가중치와, 각 특징 맵을 곱하고 더하여 (linear combination) ReLU를 덮어씌웁니다.
클래스의 interest에서 양의 값의 영향에 관심이 있기 때문에 렐루를 붙였습니다.
그리고 결과적으로 더 좋은 CAM을 만들었음을 실험으로 밝혔습니다.
Grad-CAM as a generalization to CAM

각 클래스에 대한 스코어 S를 얻기위해 다음과 같은 식을 이용할 수 있습니다.

이로써 Grad-CAM은 CAM의 일반적인 정의라고 볼 수 있습니다.
정리해보면 다음과 같습니다.
3개의 클래스를 구분한다고 가정을 해봅시다.
각 클래스는 0, 1, 2로 label이 될 것이고, 모델을 통과한 이미지(256, 256, 3)는 softmax값으로 (1, 3) 각 클래스일 확률벡터를 출력할 것입니다.
여기서 1번 클래스의 GradCAM(256, 256, 3)을 구해봅시다.
# keras
# 클래스 1번에 대한 CAM을 구해봅시다.
from keras.applications.vgg16 import VGG16
from keras import backend as K
NUM_CLASS = 3 # 0, 1, 2
model = VGG16(weights='imagenet')
class1_output = model.output[:, 1]
# e.g. 'block5_conv3' in VGG16 model
last_conv_layer = model.get_layer('last_conv_name')
# 특정 클래스 c(여기서는 1)의 gradient ( dy/dA )
grads = K.gradients(class1_output, last_conv_layer.output)[0]
pooled_grads = K.mean(grads, axis=(0, 1, 2)) # 특성맵 채널별 gradient 평균값이 담긴 벡터
# 모델의 인풋을 입력으로 받고, pooled_grads와 컨볼루션 마지막층의 아웃풋을 출력으로 하는 함수설정
iterate = K.function([model.input],
[pooled_grads, last_conv_layer.output[0]])
pooled_grads_value, conv_layer_output_value = iterate([x])
# 클래스 1번에 대한, 채널의 중요도를 특성 맵 배열의 채널에 곱합니다.
# linear combination
for i in range(NUM_CLASS):
conv_layer_output_value[:, :, i] *= pooled_grads_value[i]
# 채널 축(axis=-1)에 따라서 평균한 값이 CAM 입니다.
heatmap = np.mean(conv_layer_output_value, axis=-1)
# ReLU
gradCAM = np.maximum(heatmap, 0)
# 0~1 사이로 정규화
gradCAM /= np.max(gradCAM)
plt.matshow(heatmap)
<출처: 케라스 창시자에게 배우는 딥러닝, p.238>, 필자가 조금 수정
여기서 만들어진 Grad-CAM을 원본이미지와 비교할 수 있게 만들수 있고,
논문에서는 Grad-CAM을 Guided Backprop를 합쳐 Guided Grad-CAM을 만들었습니다.
4. Evaluating Localization
얻어낸 GradCAM 이미지로 모델이 어디를 보고 예측을 하는 가에 대한 정보를 알 수 있었습니다.
이에 추가로 우리는 label없이 물체의 위치를 알 수 있는 Weakly-supervised localization을 할 수 있게 됩니다.
여기서 weakly-supervised가 붙은 이유는, CAM을 얻기위해 label이 있는 데이터로 사전학습이 필요하기 때문입니다.
4.1 Weakly-supervised Localization

evaluation 영역에서, Grad-CAM의 localization error는 c-MWP이나 CAM보다 낮았습니다.
4.2 Pointing Game
'포인팅 게임'이란 한 이미지에서 다른 오브젝트들을 찾아내는 attention map들 식별을 잘하는 정도를 평가하는 것입니다.
attention map의 각 객체가 실제 ground truth의 객체에 해당하는 지 hit과 miss 개수를 세어서 정확도(=hit/(hit+miss)) 를 계산합니다.
여기서 Grad-CAM은 기존 방법인 c-MWP를 가볍게 이겼습니다. (70.58% vs. 60.30%)
5. Evaluating Visualizations
5.1 Evaluating Class Discrimination
Guided Grad-CAM은 사람이 물체를 판단하는 능력을 더 올려주었습니다.
5.2 Evaluating Trust
두가지 예측된 설명으로부터, 무엇이 더 좋은 설명인지 평가하고 싶었고, VGG-16과 AlexNet으로 mAP를 비교했습니다.
5.3 Faithfulness vs. Interpretability
위 둘의 관계는 tradeoff 관계로, faithfulness를 올리려면 interpretability가 낮아지게 됩니다.
Grad-CAM은 faithful, interpetabel 둘다 했다고 합니다.
6. Diagnosing image Classification CNNs
6.1 Analyzing Failure Modes for VGG-16

6.2 Effect of adversarial noise on VGG-16

6.3 Identifying bias in dataset
7. Counterfactual Explanations
저자는 새로운 해석 양식(explanation modality)를 제안했습니다.
counterfactual explanation인데요, 이는 네트워크의 결정을 바꾸는데 영향을주는 지역을 강조하는 것입니다.
여기서 나타낸 지역을 배제하고 나머지를 이용해 클래스를 판단한다는 것이지요.
아래 그림을 보시면, cat을 찾아내기 위해 dog을 배제한 모습을, 그리고 그 반대경우를 볼 수 있습니다.

방법은 간단한데, 위에서 정의한 neuron importance weights에서 뒤에 gradient에 -를 붙여 새로운 양식을 만들었습니다.

8. Image Captioning and VQA
논문 저자는 Grad-CAM을 가지고 여러실험을 많이했는데요, 그 중 마지막은 VQA(Visual Question Answering)입니다.
아래 사진을 보시면, 모델이 무엇을 보고 이미지에 대한 대답을 해주는지 그 근거를 말해주고 있습니다.

9. Conclusion
- Grad-CAM(Gradient-weighted Class Activation Map)을 사용함으로써 시각적인 설명을 제공함으로써 더 안이들여다 보이는 (더 이상 블랙박스가 아닌) CNN기반 모델을 만들 수 있었습니다.
- Grad-CAM을 통해 고해상도의 클래스를 구분하는 Guided Grad-CAM 시각화를 얻었습니다.
- 만들어낸 시각화는 기존의 weakly-supervised localization과 pointing, faithfulness 방법들의 성능을 뛰어넘었습니다.
- AI 시스템이 지능적일 뿐만 아니라, 사람이 AI를 신뢰할 수 있도록 AI가 판단한 근거나 행동들의 이유를 제시할 수 있어야 한다. Grad-CAM과 같은 연구가 이를 도와줄 것입니다.
-감사합니다-
'ML, DL > 논문' 카테고리의 다른 글
| [GAN for Data Augmentation] DAGAN, 2018 (0) | 2019.10.05 |
|---|---|
| [GAN] Data Augmentation Using GANs, 2019 (0) | 2019.09.21 |
| Faster R-CNN, 2016 (0) | 2019.08.06 |
| Cascade R-CNN, Cai et al, 2018 (0) | 2019.08.04 |
| [MMDetection] 논문 정리 및 모델 구현 (1) | 2019.07.28 |



댓글