
이 글에서는 여러 가지 클래스를 분류하는 Classification 문제에서,
Cross entropy를 사용하는 방법와 원리를 알아봅니다.
1. Tasks
우선, 두가지 문제를 봅시다.

1-1) Multi-Class Classfication
각 샘플(이미지)은 클래스 C 중 하나로 분류될 수 있습니다.
해는 0번, 즉 [1 0 0] (원핫인코딩),
달은 1번, [0 1 0],
구름은 2번, [0 0 1]
으로 분류될 수 있다는 말입니다.
CNN은 s(scores) 벡터를 출력하고, one hot 벡터인 타겟(ground truth) 벡터 t와 매칭이 되어 loss값을 계산할 것입니다.
즉, Multi-Class Classification은 여러 샘플(이미지)에서 C개의 클래스 중 하나의 클래스로 분류하는 문제로 생각할 수 있습니다.
1-2) Multi-Label Classficiation
위의 그림 중 오른쪽 그림을 참고하시면 됩니다.
각 샘플은 여러 개의 클래스 객체(object)를 가질 수 있습니다.
타겟 벡터 t는 하나 이상의 positive클래스를 가질 수 있고 [1 0 1] 처럼 인코딩 될 수 있습니다.
즉, Multi-label Classification은 여러 샘플(이미지)에서 각 샘플 마다 있는 클래스 들을 여러 클래스로 레이블하는 문제입니다.
그럼 Multi-Class와 Multi-label 분류에 사용되는 활성화 함수(activation function)와 손실함수(loss function)를 알아보겠습니다. 아, 그 전에 간단한 활성화 함수를 알아보도록 하죠.
2. 활성화 함수(Activation Function)
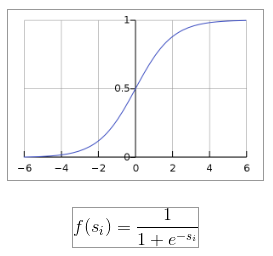
Sigmoid
CNN 마지막 층에서 나온 값을 (0, 1) 사이 값으로 압축하여 줍니다.
각 요소 $s_i$에서 각각 적용될 수 있습니다. logistic function이라고 불리기도 합니다.
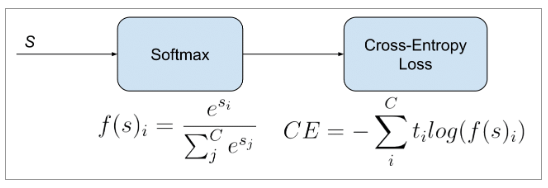
Softmax
클래스의 스코어를 나타내는 벡터 각각의 요소는 (0, 1) 범위가 되며, 모든 합이 1이 되도록 만들어줍니다.
$s_j$는 각 스코어 이고 모든 i에 대한 소프트맥스값을 더하면 1이 나옵니다.
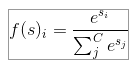
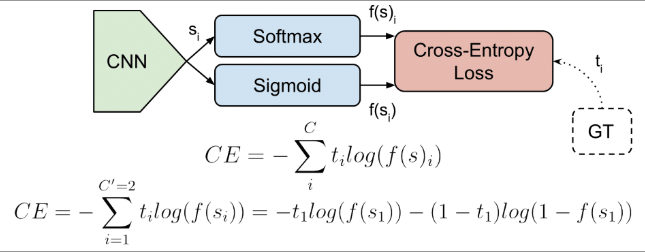
3. Loss
3.1) Cross-Entropy Loss
드디어 크로스 엔트로피가 나왔습니다. CE loss는 다음과 같이 정의될 수 있습니다.
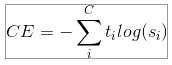
$t_i$ 는 ground truth (정답), $s_i$는 각 클래스 i에 대한 CNN 마지막 층의 아웃풋인 score 벡터의 i번째 요소입니다.
(0, 1) 사이 계산 범위를 맞추기 위하여 스코어는 위에서 설명한 sigmoid activation function과 종종 같이 붙어서 CE loss와 계산됩니다.
특별히 binary classfication 문제에서는 (즉, C' = 2), 식을 전개해보면 다음과 같이 나옴을 알 수 있습니다.
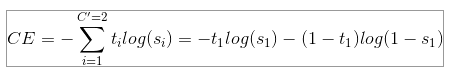
3.2) Categorical Cross-Entropy Loss
Softmax activation 뒤에 Cross-Entropy loss를 붙인 형태로 주로 사용하기 때문에 Softmax loss 라고도 불립니다.
→ Multi-class classification에 사용됩니다.
우리가 분류문제에서 주로 사용하는 활성화함수와 로스입니다. 분류 문제에서는 MSE(mean square error) loss 보다 CE loss가 더 빨리 수렴한 다는 사실이 알려져있습니다. 따라서 multi class에서 하나의 클래스를 구분할 때 softmax와 CE loss의 조합을 많이 사용합니다.
널리 쓰이는 프레임워크 3가지에서는 multi-class에서 쓸 수 있는 cross entropy loss를 정의해놓았습니다.
물론 이는 binary class에서도 적용이 가능합니다. 클래스가 2개일 때 sigmoid와 softmax는 같은 식이 됩니다.
- Caffe: SoftmaxWithLoss Layer
- Pytorch: torch.nn.CrossEntropyLoss
- TensorFlow: tf.nn.softmax_cross_entropy (deprecated) → tf.nn.softmax_cross_entropy_v2
3.3) Binary Cross-Entropy Loss
Sigmoid activation 뒤에 Cross-Entropy loss를 붙인 형태로 주로 사용하기 때문에 Sigmoid CE loss라고도 불립니다.
→ Multi-label classification에 사용됩니다.
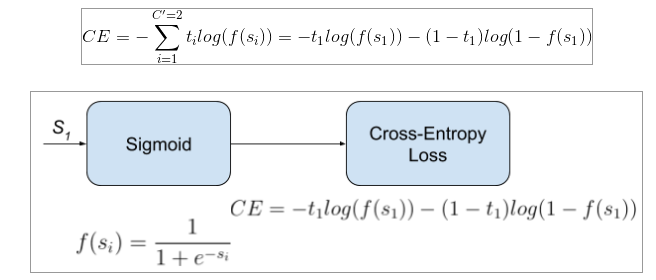
- Caffe: Sigmoid Cross-Entropy Loss Layer
- Pytorch: torch.nn.BCEWithLogitsLoss
- TensorFlow: tf.nn.sigmoid_cross_entropy_with_logits
4. Focal loss
Focal loss는 페이스북의 Lin et al. 이 소개했습니다. --> 논문참고 [https://arxiv.org/abs/1708.02002\]
RetinaNet 모델을 학습시키는데 Focal loss가 한단계 객체 탐색기를 향상시킵니다.
Focal loss는 분류 에러에 근거한 loss에 가중치를 부여하는데,
샘플이 CNN에 의해 이미 올바르게 분류되었다면 그것에 대한 가중치는 감소합니다.
즉, 좀 더 문제가 있는 loss에 더 집중하는 방식으로 불균형한 클래스 문제를 해결하였습니다.
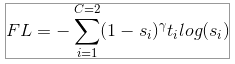
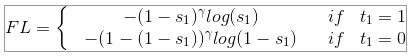
Focal loss는 Sigmoid activation을 사용하기 때문에, Binary Cross-Entropy loss라고도 할 수 있습니다.
특별히, r = 0 일때 Focal loss는 Binary Cross Entropy Loss와 동일합니다.
tensorflow로 기반한 keras 코드는 다음과 같습니다.
from keras import backend as K
import tensorflow as tf
# Compatible with tensorflow backend
def focal_loss(gamma=2., alpha=.25):
def focal_loss_fixed(y_true, y_pred):
pt_1 = tf.where(tf.equal(y_true, 1), y_pred, tf.ones_like(y_pred))
pt_0 = tf.where(tf.equal(y_true, 0), y_pred, tf.zeros_like(y_pred))
return -K.mean(alpha * K.pow(1. - pt_1, gamma) * K.log(pt_1))
- K.mean((1 - alpha) * K.pow(pt_0, gamma) * K.log(1. - pt_0))
return focal_loss_fixed
pytorch에서는 다음과 같습니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class FocalLoss(nn.Module):
def init(self, gamma=0, alpha=None, size_average=True):
super(FocalLoss, self).init()
self.gamma = gamma
self.alpha = alpha
if isinstance(alpha,(float,int,long)): self.alpha = torch.Tensor([alpha,1-alpha])
if isinstance(alpha,list): self.alpha = torch.Tensor(alpha)
self.size_average = size_average
def forward(self, input, target):
if input.dim()>2:
input = input.view(input.size(0),input.size(1),-1) # N,C,H,W => N,C,H*W
input = input.transpose(1,2) # N,C,H*W => N,H*W,C
input = input.contiguous().view(-1,input.size(2)) # N,H*W,C => N*H*W,C
target = target.view(-1,1)
logpt = F.log_softmax(input)
logpt = logpt.gather(1,target)
logpt = logpt.view(-1)
pt = Variable(logpt.data.exp())
if self.alpha is not None:
if self.alpha.type()!=input.data.type():
self.alpha = self.alpha.type_as(input.data)
at = self.alpha.gather(0,target.data.view(-1))
logpt = logpt * Variable(at)
loss = -1 * (1-pt)**self.gamma * logpt
if self.size_average: return loss.mean()
else: return loss.sum()
'ML, DL > Concept' 카테고리의 다른 글
| [ML] Semi-supervised Learning, Transfer Learning 설명 (599) | 2019.11.23 |
|---|---|
| [Regularization] 규제, 모델 일반화능력 향상, Model generalization (970) | 2019.10.07 |
| [DL] 딥러닝 성능 향상(전처리, 가중치초기화, 모멘텀, 활성함수) (0) | 2019.09.24 |
| 교차 엔트로피(Cross Entropy)와 로그우도(Log Likelihood) (2) | 2019.08.29 |
| [ML] K-Fold Cross Validation (K겹 교차검증) (0) | 2019.08.02 |




댓글