
Abstract
9.2M 개의 이미지
- 19.8k개의 concept에 대한 3천10만개의 이미지-레벨 레이블
- 600개의 object class에 대한 1천5백4십만개의 bounding box
- 57개의 class에 대한 visual relationship 표기가 3십만7500개 이다.
이 데이터들은 image classification, object detection, visual relationship detection 영역의 발전에 사용되기를 바라고 있다.
1. Introduction

이미지 소개
2. Dataset Acquisition and Annotation
2.1 Image Acquisition
2.2 Classes
2.3 Image-Level Lables
이미지를 분류하는 것은 시간도 많이 걸리고, 애매한 경우도 있어서 사람에게 힘든 작업이기 때문에, 이미지 분류기를 먼저 만든 다음에, 모든 이미지에 대해서 후보 라벨을 만든 후, 사람에게 이것을 검증하도록 하였다. 클래스가 해당 이미지에 있으면 positive, 클래스가 없으면 negative 라벨을 붙였다. 물론 아쉽게도 다른 확인되지 않은 다른 라벨도 존재할 수 있다.박스를 그릴 수 있는 클래스에 대한 계층구조 맵을 그렸다. 어떻게 그렸는지 놀랄 정도로, 보면 정말 장관이다. [https://storage.googleapis.com/openimages/2018_04/bbox_labels_600_hierarchy_visualizer/circle.html]
2.4 bounding boxes
- perfect box를 '모든 보이는 객체의 부분을 포함하는 가장 작은 박스'라고 정의했다.
- top, bottom, left-most, right-most point 네 점을 클릭해서 그렸다.
- 여러 바운딩 박스를 그릴 수 있으면, 가장 그럴듯한 박스를 사람이 골라 검증하였다.
- "Hierarchical de-duplication": animal, zebra와 같이 같은 object에 두 가지의 label이 붙어서 2개의 bbox가 그려지는 것을 막기 위해 다음과 같은 방법을 사용했다.
-- train set의 경우 이미지-레벨 레이블에 이미지 존재하고 있는 레이블의 상위 클래스는 삭제하였다. 예를 들면, animal, zebra, car 레이블이 이미지에 있으면, zebra와 car만 표기했다.
-- validation, test set의 경우 더 엄격한 규칙을 적용시켰다. 처음에 모든 가증한 레이블에 대한 박스를 그리게 한 뒤, child class(e.g. zebra)와 parent class(e.g. animal)가 IoU > 0.8 겹치면 parent box를 제거하였다..
2.5 visual relationship
<class1, relationship, class> 형식으로 triplets을 골랐다.
e.g. <woman, playing, guitar>, <bottle, on, table>
3. Statistics

3.1 Human-Verified Image-Level Labels

3.2 Bounding Boxes
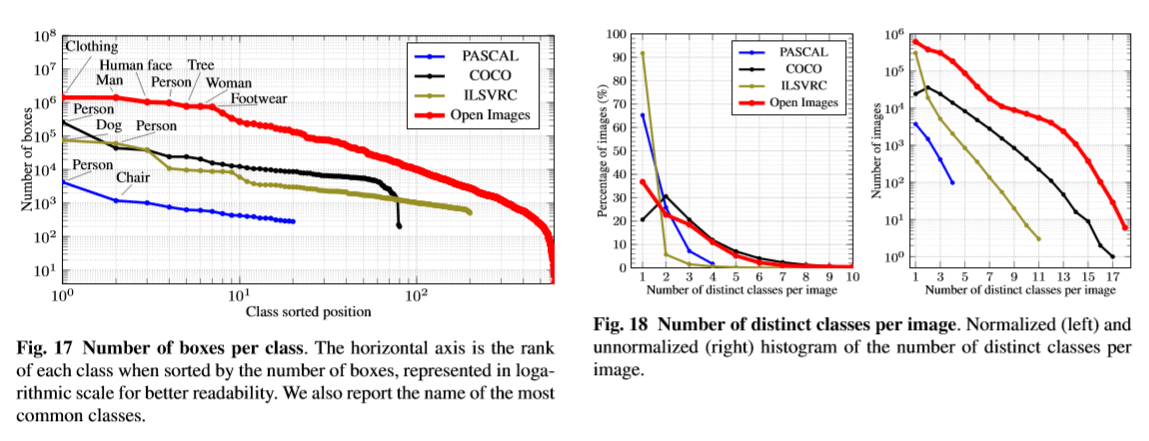
일반적인 통계

PASCAL, COCO, ILSVRC-Det 데이터 보다 클래스 수, 박스 수, 데이터 수가 압도적으로 많다.

Box attributes 통계
뿐만 아니라 여러 속성도 통계를 내었다.
- Occluded : 다른 물체에 가려진 박스
- Truncated : 이미지 영역에서 벗어나 끝이 잘린 박스, occluded와 함께 주로 나타나는 속성이다.
- GroupOf : 군중이 모여있거나, 한 빌딩에 여러개의 창문이 있을 때 등에 그룹으로 박스를 적용한다.
- Depiction : 다른 클래스를 묘사한 클래스이다.
- Inside : 어떤 object의 내부를 의미한다. (e.g. 빌딩 내부 ) 이 속성은 많이 없는 속성이다.

Box class 통계
person 클래스의 인스턴스 수는 3,505,362개나 있고, 이건 사실 사람을 지칭 하는 여러 클래스(person, women, man, girl, boy)의 집합체 이다.
각각의 object는 가장 하위레벨의 클래스 라벨로만 표기되어 있다.예를 들어 man 은 하나의 box만 가지고 있고, person으로 표기되어 있지 않다.


Box size 통계
통계를 보면, 전체 박스의 43%가 이미지사이즈의 1% 영역을 차지하는 박스들이다. 이런 데이터는
작은 영역을 더 잘 관찰할 수 있는 딥러닝 모델을 만드는 데 도움이 될 것이다!

3.3 Visual Relationships
4. Quality
4.1 bounding boxes
5 Performance of baseline models
6 Credits
데이터 분석 작업이라서 그런지, 이 논문에 기여하신 분이 참많다.
7. Conclusions
9천2백만 개의 이미지 데이터가 classification, object detection, visual relationship detection에 사용 될 수 있다.
데이터가 어떻게 모아졌는지 설명하였고, 데이터 통계분석에 대한 깊은 이해를 제공했고,
quality를 평가했으며, 몇몇의 modern model로 시험해 보았다.
이 데이터가 이 분야의 발전에 도움을 주었으면 좋겠다!
'ML, DL > 논문' 카테고리의 다른 글
| Grad-CAM(Gradient-weighted Class Activation Mapping), 코드포함 (6) | 2019.08.08 |
|---|---|
| Faster R-CNN, 2016 (0) | 2019.08.06 |
| Cascade R-CNN, Cai et al, 2018 (0) | 2019.08.04 |
| [MMDetection] 논문 정리 및 모델 구현 (1) | 2019.07.28 |
| Mask-RCNN (0) | 2019.07.16 |



댓글